
Anyone that is using AI in any volume will have come up against usage limits at some point. It is becoming more frequent. Whether you are facing unexpected credit-card charges, or paused for a period of time as you hit your daily/monthly allowance, AI billing is anything but transparent.
In the world of Large Language Models, a token is the fundamental unit of information that a model processes. AI models do not read text word by word or letter by letter like humans. Instead, they break down sentences into smaller chunks to understand patterns and predict what comes next. In English, a good rule of thumb is that 1,000 tokens are roughly equal to 750 words. This ratio changes depending on the language and the complexity of the text.
You are charged for not only the tokens you pass into the AI, but also the amount of tokens it returns. Each model has a different pricing (usually expressed in per-million tokens), with the latest releases costing a little more. More specialized ones, that deal with video/images/voice, will have different rates for their token usage.
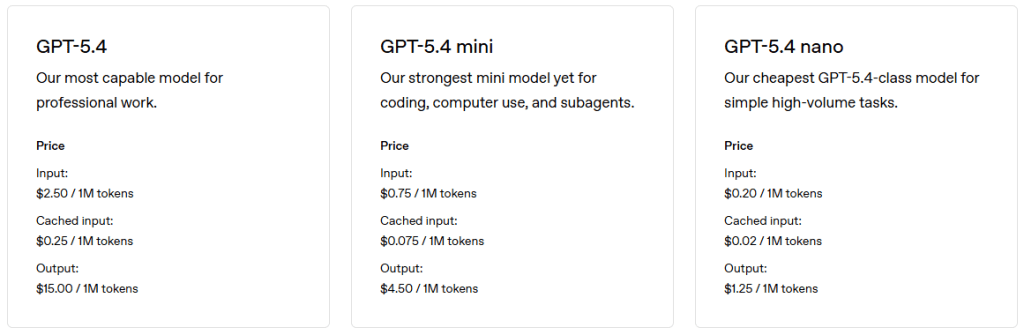
The various providers will tell you just how many tokens a given API call cost you (assuming you are calling the API). If you are using your typical Cursor/Claude/ChatGPT chat client, then you have no real handle on the amount of tokens that are being consumed, as you are happily chatting back and forth.
We are forced to trust the AI vendors that their determination of token count is fair. It is not regulated or reviewed by an independent 3rd party. We’re basically digital addicts, sitting at the feet of the AI pushers, being told just how much a given interaction cost.
It gets a little more “fuzzy” when we start uploading photos, documents, code bases and ask our AI overlords to interact. Take images for example. We process literally millions of images a week, and we record every usage metric the API gives us. We’ve discovered that the same image, with the same prompt, to the same model, can reduce wildly different token usage patterns. We are told to expect some variability as the LLM execution path through the neural net will differ on each invocation.
Keeping things to a minimum context, tightening up prompts (though we are constantly being told to be more verbose to give the AI better context – mmm but doesn’t that also cost more too? the cynic in me notes this is very convenient advice), is suppose to help reduce our token usage. The AI vendors don’t want us to reduce our token usage – they need the income. Like the early electricity company’s – keep plugging in those high-powered devices and don’t think of the bill coming at the end of the month.
For those not on a company budget, I have seen people advise signing up to the AI vendors with a virtual credit-card from Privacy (https://www.privacy.com/) with preset limits so you don’t get unexpected bills. Recently Claude gave “off-peak hours” token bonus allowances.
I have noticed though in the past recent months, more controls are being made available to those that run team accounts. Now I can put individual spending limits, I can also put a limit on the account as a whole. This is a good first step – however, I still only get a report on token usage for an individual – I have no clue what that really translates into.
AI pricing needs to be rethought. Token usage was “fine” initially, but not all AI asks are the same, and instead it should be more based on the computing power that was consumed. Some are already experimenting with this. Ollama are stepping away from explicit token based pricing, and instead going more towards GPU time. Some vendors charge on the minutes of audio/video you want to process.

Local models of course do not suffer from this token usage limitation. That is more of an CapEx problem, with the initial hardware investment depending on the throughput and size of model you want to host. This is not going to be a cheap/viable option anytime soon. While it is cool to run a local model, it is a very slow experience, and you soon come to appreciate just how fast the cloud providers are, even with the network latency.
I don’t want the AI vendors to stop charging. They need to charge, to stay in business and continue to provide me with their services. However, they need to make it not feel like a Mafia style shake down (I’ll tell you how much you owe me) every time I ask to do something.

Electric evolved – the device I plug into the wall, has a wattage rating on it, so I can calculate how much power it is going to consume before I ever plug it in. Sure they will add in their various standing charges, taxes and what have you but at least I, as the consumer, have an informed decision just how much plugging in my toaster oven is going to cost me. Hitting “Enter” on my prompt, I have no clue.
I want more transparency. Transparency gives me more decision points on how I can use and maximum my token usage. I would like on/off peak rates, as there are agents I can hold back and let them run while I happily sleep at night (yes, contrary to popular opinion I do sleep at times).
Transparency lets me budget better and present my CFO with predictable numbers that I have a fighting chance of standing behind.
AI Disclaimer: Gemini Nano Banana Pro was used to generate the photo – from the 1972 The Godfather.





